Figure 1. shows an example of an annotation saved to an XML document. The document contains a Text annotation that contains the string “Text Annotation”. This example provides an overview of the XML template used by the Annotation SDK.
Figure 1 – Example of an annotation stored in an XML document
The basic rules and requirements are listed below:
· XML documents used by Annotation SDK are well-formed, following all the basic requirements in syntax and structure. For more information, please consult the XML reference.
· Every XML document created by the Annotation SDK begins with a BOM (byte order mark), followed by an XML declaration shown in Figure 2 (identical to the one shown at the start of Figure 1). The encoding of the XML document is UTF-16 to ensure there are no conversion problems during the reading and writing process.
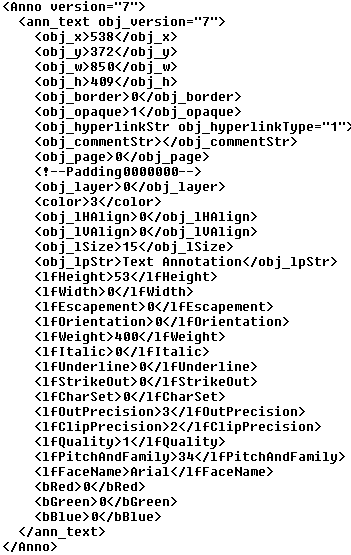
Figure 2 – XML declaration and copyright string
· The XML declaration is followed by the copyright string in an XML comment, as seen on Figure 2.
· A valid XML document must contain exactly one root node, with all further nodes contained within this node. For the Annotation SDK, the root node is set to “Anno”, and each annotation object is written into the child nodes of this root node, as shown in Figure 3 (identical to the one shown in Figure 1). The root node also contains the version number of the SDK that created the annotations.
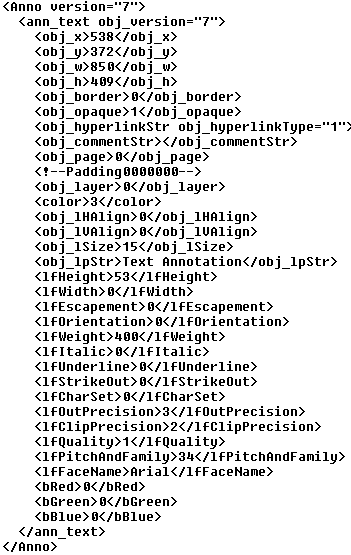
Figure 3 – XML root node and its contents
· The XML root node can contain multiple annotations. These are stored in child nodes, and the name of each child corresponds to the class name of the annotation object, for example: “ann_text”, “ann_rect”, etc. The full XML structure of each annotation object is listed in section 2.2
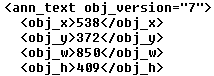
Figure 4 – XML root node, with a child node corresponding to a text annotation
· The properties of the annotation are stored in its child nodes. The name of a child node corresponds to the name of the property in the annotation (for example the X and Y coordinates, text color, etc.) The text content of the XML node contains the data in the property of the annotation.
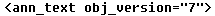
Figure 5 – XML node of a text annotation, with its properties (XY coordinates, width, and height) stored in its child nodes
· The properties of an annotation can also be written into the attributes of an XML node. The name of the XML attribute corresponds to the name of the property in the annotation, and the value of the attribute contains the data of the property. For example, the version number of an annotation object can be added as an attribute to its XML node.
o NOTE: when parsing an XML document, the attributes of an XML node are parsed first, followed by the content of the node itself. The user must make sure that the read order of the properties is consistent. If the load process requires a property to be read before another property, the properties must be stored in the correct order in the XML document. For example, if a property requires the size of the data to be known before loading the data from the XML node, the node or attribute containing the data size must come before the node containing the data.
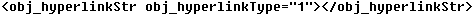

Figure 5 – Examples of XML attributes: the text annotation’s version number is stored as an attribute (“obj_version”) in the annotation XML node, and the type of the hyperlink string property is stored as an attribute (“obj_hyperlinktype”)
· The XML document may contain whitespace (for indentation and line breaks) and comments, which the parser will ignore.
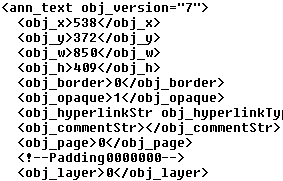
Figure 6 – Example of whitespace and comments in an XML document. The indentation improves readability for the user (child nodes are indented from the parent node’s position). The XML comment is used as padding after the “obj_page” node. Both the indentation and the comment are ignored by the parser.
· The Annotation SDK validates each XML document before loading any data from it. An XML document must follow the template described above, or it will be considered invalid. Additional requirements are listed below:
o Only one declaration is permitted, at the start of the document, exactly as shown in Figure 2.
o The XML root node must be named “Anno”, and its contents must follow the format shown in Figure 3.
o No text may be present in the XML document outside of the property nodes or XML attributes of the annotation objects.
o Outside of the types listed above, no other XML node types are allowed (for example: CDATA, ProcessingInstruction, etc.). If the parser reads such a node, the XML will be considered invalid by the SDK.